Come on try it! You know you always wanted to!
https://marketplace.sitecore.net/en/Modules/T/Tokenizer.aspx
Of my modules on the market place, this one appears to be the least used. So let me tell you about it and maybe you will give it a spin.
In most websites there is scenarios around needing to centralize content. Sometimes you can get away with storing it all in a rendering data sourced to an item, like a header, footer, or a callout. But what about a scenario where you want to be able to centralize just a specific word or a sentence?
Maybe your client has a trademarked product name that they want to make sure is always worded correctly. Maybe they have a disclaimer that needs to be included every time product a, b, and d are mentioned. Or how about a date / year that commonly shows up in content and needs to be changed on a regular basis.
This is what Tokenizer was made for! Under the hood it is a fairly simple concept. When a field is rendered we have attached a process to the pipeline that looks for matching patterns of %%([a-zA-Z0-9]+)%% . The name inside is matched against a name found in the dictionary. The value in the dictionary item then replaces the token on render.
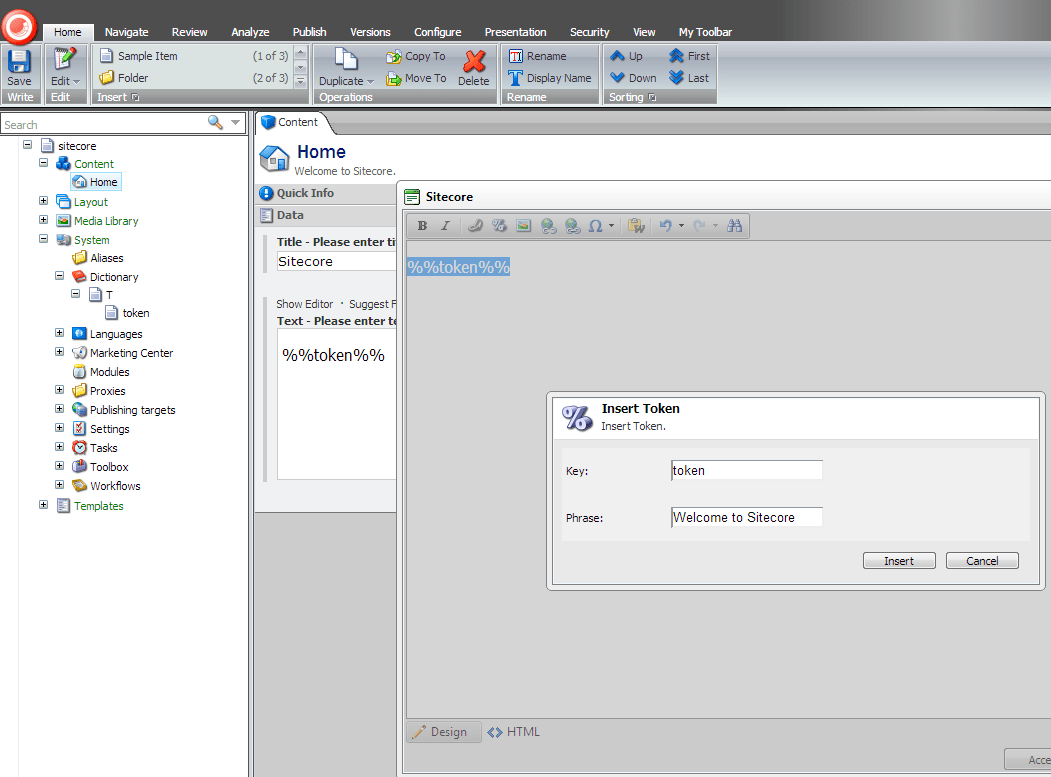
Furthermore this module includes tool that integrates with the HTML editor. As shown above, this tool allows you to manage your tokens without ever going to the dictionary. Great for those timid content authors.
Finally an important point to not miss here is that the source is fully available on the marketplace. The concept of the tokenizer could be expanded exponentially. Instead of using the dictionary you could pull data from a third party source to replace the tokens. Or maybe something complex, like some javascript you want to drop in at render. Or something logical that is dictated by a query string. As you can see this is a great tool for a starting point between allowing authors to place pretty much any type of dynamic content.
So please give it a try the next time your client talks about centralized content and let me know how it works out!
